在今年5月底,Alphago又战胜了围棋世界冠军柯洁,AI再次呈现燎原之势席卷科技行业,吸引了众多架构师对这个领域技术发展的持续关注和学习。思考AI如何做工程化,如何把我们系统的应用架构、中间件分布式架构、大数据架构跟AI相结合,面向什么样的应用场景落地,对未来做好技术上的规划和布局。
为了彻底理解深度学习,我们到底需要掌握哪些数学知识?微积分、线性代数、概率论、复变函数、数值计算等等,这些数学知识有相关性,但实际上这是一个最大化的知识范围,学习成本会非常久。金准数据归纳了理解深度学习所需要的数学知识并对他们的关系进行梳理。
一、数学原理在深度学习中的应用
1、最小二乘法
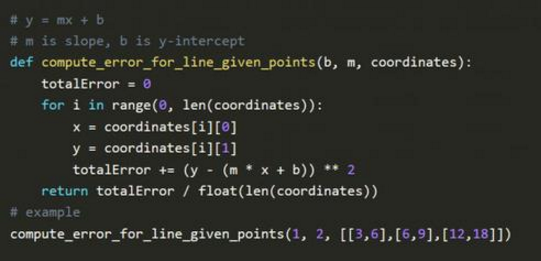
最小二乘法最初是由法国数学家勒让德(Adrien-Marie Legendre)提出的,他曾因参与标准米的制定而闻名。勒让德痴迷于预测彗星的位置,基于彗星曾出现过的几处位置,百折不挠的计算彗星的轨道,在经历无数的测试后,他终于想出了一种方法平衡计算误差,随后在其1805年的著作《计算慧星轨道的新方法》中发表了这一思想,也就是著名的最小二乘法。
勒让德将最小二乘法运用于计算彗星轨道,首先是猜测彗星将来出现的位置,然后计算这一猜测值的平方误差,最后通过修正猜测值来减少平方误差的总和,这就是线性回归思想的源头。 在Jupyter notebook上执行上图的代码。 m是系数,b是预测常数,XY坐标表示彗星的位置,因此函数的目标是找到某一特定m和b的组合,使得误差尽可能地小。
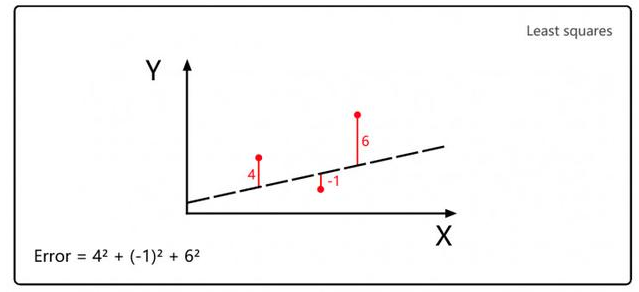
这也是深度学习的核心思想:给定输入和期望输出,寻找两者之间的关联性。
2、梯度下降
勒让德的方法是在误差函数中寻找特定组合的m和b,确定误差的最小值,但这一方法需要人工调节参数,这种手动调参来降低错误率的方法是非常耗时的。在一个世纪后,荷兰诺贝尔奖得主彼得·德比(Peter Debye)对勒让德的方法进行了改良。
假设勒让德需要修正一个参数X,Y轴表示不同X值的误差。勒让德希望找到这样一个X,使得误差Y最小。如下图,我们可以看出,当X=1.1时,误差Y的值最小。
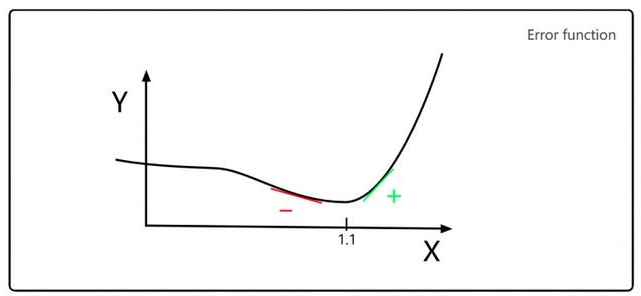
如上图,德比注意到,最小值左边的斜率都是负数,最小值右边的斜率都是正数。因此,如果你知道任意点X值所处的斜率,就能判断最小的Y值在这一点的左边还是右边,所以接下来你会尽可能往接近最小值的方向去选择X值。
这就引入了梯度下降的概念,几乎所有深度学习的模型都会运用到梯度下降。
假设误差函数 Error = X5- 2X3- 2
求导来计算斜率:
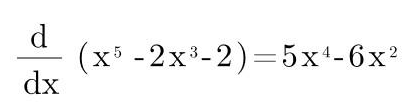
下图的python代码解释了德比的数学方法:
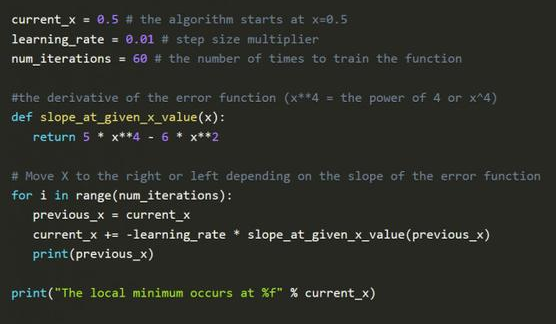
上图代码最值得注意的是学习率 learning_rate,通过向斜率的反方向前进,慢慢接近最小值。当越接近最小值时,斜率会变得越来越小,慢慢逼近于0,这就是最小值处。
举一个神经网络被用来期望在当前游戏状态下每种可能的动作所得到反馈的例子。下图给出了文章中所提到的神经网络。这个网络能够回答一个问题,比如“如果这么做会变得怎么样?”。网络的输入部分由最新的四幅游戏屏幕图像组成,这样这个网络不仅仅能够看到最后的部分,而且能够看到一些这个游戏是如何变化的。输入被经过三个后继的隐藏层,最终到输出层。
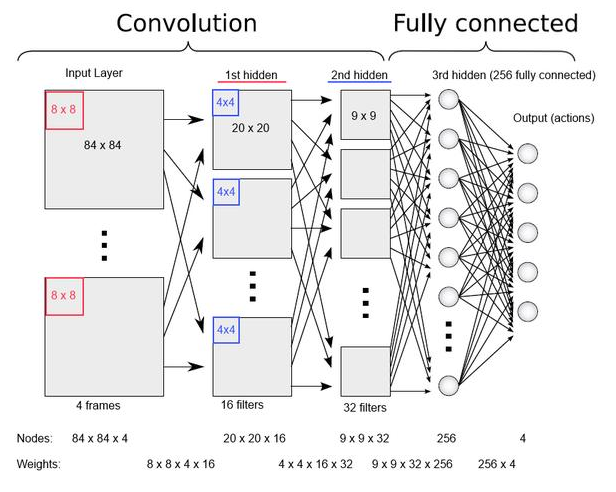
输出层对每个可能的动作都有一个节点,并且这些节点包含了所有动作可能得到的反馈。在其中,会得到最高期望分数的反馈会被用来执行下一步动作。
确切地说,在定义了网络的结构之后,剩下唯一会变化的就只有一件事:连接之间的强弱程度。调整这些方式地权重,从而使得通过这个网络的训练样例获得好的反馈,可以选择通过将梯度下降与激励学习方法结合的方式。
这个网络不仅仅需要最大化当前的反馈,还需要考虑到将来的动作。这一点可以通过预测估计下一步的屏幕并且分析解决。用另一种方式讲,可以使用(当前反馈减去预测反馈)作为梯度下降的误差,同时会考虑下一幅图像的预测反馈。
3、线性回归
线性回归算法结合了最小二乘法和梯度下降。在二十世纪五六十年代,一组经济学家在早期计算机上实现了线性回归的早期思想。他们使用穿孔纸带来编程,这是非常早期的计算机编程方法,通过在纸带上打上一系列有规律的孔点,光电扫描输入电脑。经济学家们花了好几天来打孔,在早期计算机上运行一次线性回归需要24小时以上。
下图是Python实现的线性回归。

梯度下降和线性回归都不是什么新算法,但是两者的结合效果还是令人惊叹。
4、感知机
感知机最早由康奈尔航空实验室的心理学家弗兰克·罗森布拉特(Frank Rosenblatt)提出,罗森布拉特除了研究大脑学习能力,还爱好天文学,他能白天解剖蝙蝠研究学习迁移能力,夜晚还跑到自家屋后山顶建起天文台研究外太空生命。1958年,罗森布拉特模拟神经元发明感知机,以一篇《New Navy Device Learns By Doing》登上纽约时报头条。
罗森布拉特这台机器很快吸引了大众视线,给这台机器看50组图片(每组由一张标识向左和一张标识向右的图片组成),在没有预先设定编程命令的情况下,机器可以识别出图片的标识方向。

每一次的训练过程都是以左边的输入神经元开始,给每个输入神经元都赋上随机权重,然后计算所有加权输入的总和,如果总和是负数,则标记预测结果为0,否则标记预测结果为1。
如果预测是正确的,不需要修改权重;如果预测是错误的,用学习率(learning_rate)乘以误差来对应地调整权重。
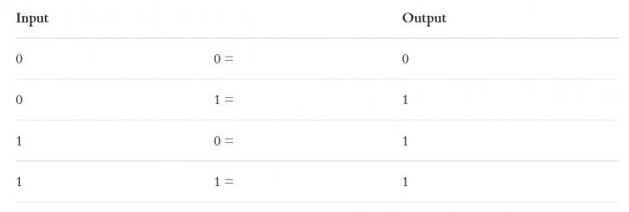
下面我们来看看感知机如何解决传统的或逻辑(OR)。
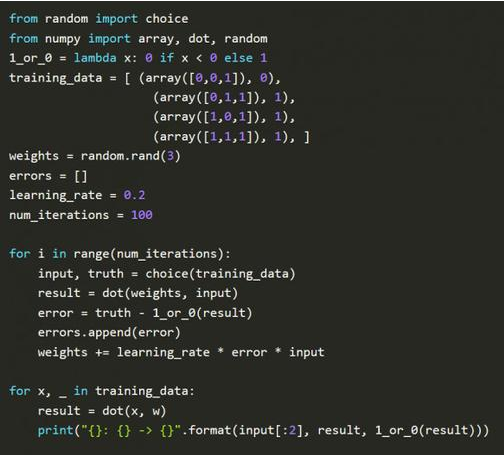
Python实现感知机:
等人们对感知机的兴奋劲头过后,马文·明斯基(Marvin Minsky)和西摩·帕普特(Seymour Papert) 打破了人们对这一思想的崇拜。当时明斯基和帕普特都在MIT的AI实验室工作,他们写了一本书证明感知机只能解决线性问题,指出了感知机无法解决异或问题(XOR)的缺陷。
在明斯基和帕普特提出这一点的一年后,一位芬兰的硕士学生找到了解决非线性问题的多层感知机算法。当时因为对感知机的批判思想占主流,AI领域的投资已经干枯几十年了,这就是著名的第一次AI寒冬。
明斯基和帕普特批判感知机无法解决异或问题(XOR,要求1&1返回0):
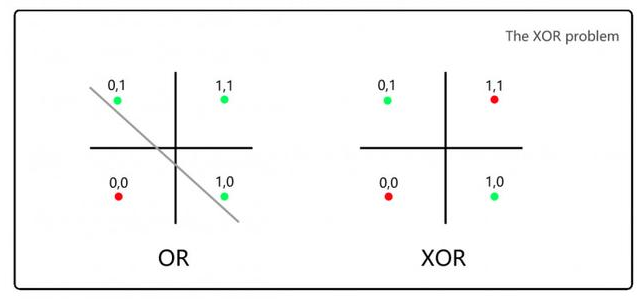
对于左图的OR逻辑,我们可以通过一条线分开0和1的情形,但是对于右边的XOR逻辑,无法用一条线来划分。
5、人工神经网络
到了1986年,鲁梅尔哈特(David Everett Rumelhart)、杰弗里·辛顿(Geoffrey Hinton)等人提出反向传播算法,证明了神经网络是可以解决复杂的非线性问题的。当这种理论提出来时,计算机相比之前已经快了1000倍。
为了理解这篇论文的核心,我们实现了DeepMind大神Andrew Trask的代码,这并不是随机选择的代码,这段代码被Andrew Karpathy斯坦福的深度学习课程、Siraj Raval在Udacity的课程中采用。更为重要的是,这段代码体现的思想解决了XOR问题,融化了AI的第一个冬季。
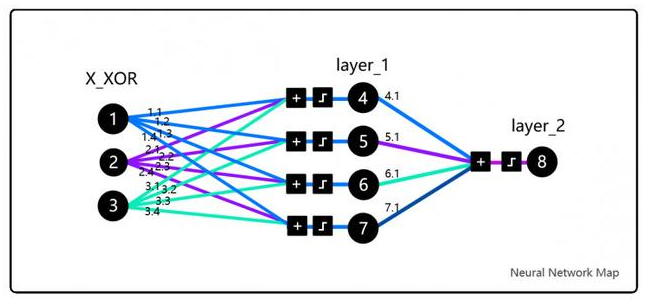
在我们继续深入之前,读者可以试试这个模拟器,花上一两个小时来熟悉核心概念,然后再读Trask的博客,接下来多熟悉代码。注意在X_XOR数据中增加的参数是偏置神经元(bias neurons),类似于线性函数中的常量。
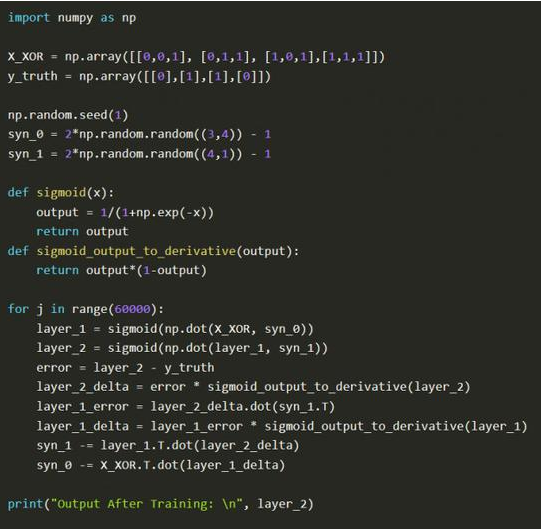
先注重去看背后的逻辑,不要想着一下子就能完全参透全部。
6、深度神经网络
深度神经网络指的是除了输入层和输出层,中间还存在多层网络的神经网络模型,这一概念首先由加利福尼亚大学计算机系认知系统实验室的Rina Dechter提出,可参考其论文《Learning While Searching in Constraint-Satisfaction-Problems》,但深度神经网络的概念在2012年才得到主流的关注,不久后IBM IBM Watson在美国智力游戏危险边缘(eopardy)取得胜利,谷歌推出了猫脸识别。
深层神经网络的核心结构仍保持不变,但现在开始被应用在不同的问题上, 正规化也有很大的提升。一组最初应用于简化噪音数据的数学函数,现在被用于神经网络,提高神经网络的泛化能力。
深度学习的创新很大一部分要归功于计算能力的飞速提升,这一点改进了研究者的创新周期,那些原本需要一个八十年代中期的超级计算机计算一年的任务,今天用GPU只需要半秒钟就可以完成。
计算方面的成本降低以及深度学习越来越丰富的库资源,使得大众也可以走进这一行。我们来看一个普通的深层学习堆栈的例子,从底层开始:
GPU > Nvidia Tesla K80。通常用于图像处理,对比CPU,他们在深度学习任务的速度快了50-200倍。
CUDA > GPU的底层编程语言。
CuDNN > Nvidia优化CUDA的库
Tensorflow > Google的深度学习框架
TFlearn > Tensorflow的前端框架
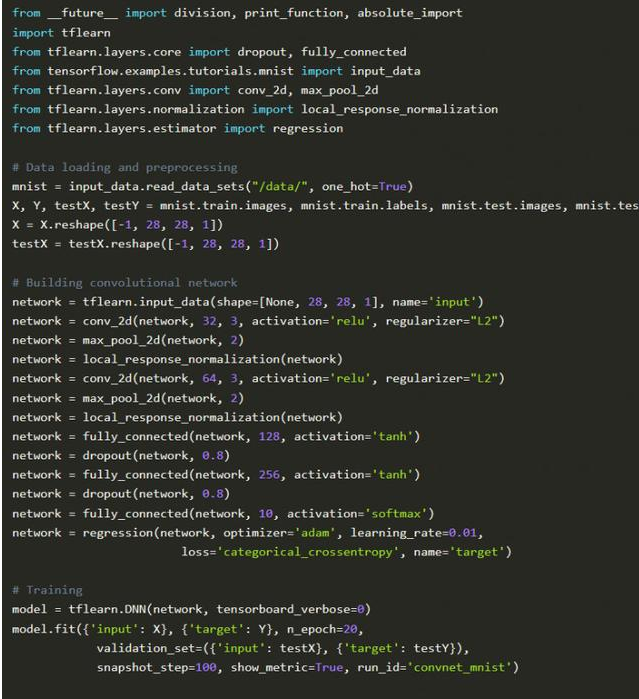
举一个数字分类的例子(MNIST数据集),这是一个入门级的例子,深度学习界的“hello world”。

在TFlearn中实现:
二、数学原理可能是深度学习神经网络的数据瓶颈
像大脑一样,深度神经网络有层层神经元(只不过是用数据节点模拟的)。当数据节点被激发时,它会发送信号到它上层中连接的其它数据节点。在深度学习期间,节点网络中的连接会根据被激发的频率被扩展加强或缩小减弱,如同人类的神经网络一般。
比如输入的数据如果是一张狗的照片,每个像素可以看作是激发最底层的数据节点的信号,这些信号通过了数据节点网络不断向上层发射,最终获得了一个结论。而大量的狗的照片被输入以后,这些结论就会在高层数据节点上有一个相近的区域,而我们可以手动的把这个区域定为“狗”。从此,只要是狗的照片,经过了这个数据节点网络以后,就会在很大的概率上落入这个区域。这就是数据神经网络最基础的原理。但是这种能够产生和人类智慧类似(或者本质上一样)的数学原理究竟是什么呢?这是人工智能界的专家很想了解的,甚至我们也可以从中学会人类的大脑是用什么方式来理解现实。
人类的大脑是如何从我们日常的感官中筛选信号并将其提升到自我意识水平的谜团驱使了数据学的先驱者对深度学习神经网络的兴趣,他们希望模仿大脑的设计来逆向学习它的运行规则。然而今天人工智能从业者已经不是很关心这个最初的愿望,而是更关心如何应用这个没有被完全解释的(甚至是根本没有被解释的)现象。现在人类已经有建立超越人脑神经元的数据节点的能力,并且在不断追求更快更大的数字神经网络,但是这是否符合自然生物学上的合理性呢? 我们是否应该在深度神经网络进一步发展前花更大的精力去探索一下它的原理呢?
很明显的,人类的学习能力和深度学习数据神经网络并不完全一样。比如,一个刚刚开始学习识字的儿童并不需要看过成千上万个同样的字才能理解它和其它字之间的区别。很多情况下,人类只需要看过一次,就能领会这个字和其它文字的区别。
同样的,你不需要看见人数百次才能区分这个是人,你甚至可以看一次就知道他或她是人,而且你还可以把他或她从其它人直接区分出来。当然了,这对深度学习网络来说不是完全不可能的。一种方式是将事物进行降级分解,比如把人的五官从面部分类出来,比对其和其它五官的吻合度,然后再对整体的结构和比例进行匹配。这可以大幅降低深度学习网络的训练时间。但是即便如此,也难以做到类似人类的判断能力。
三、总结
深度学习的主要思想仍然很像多年前罗森布拉特提出的感知机,但已经不再使用二进制赫维赛德阶跃函数(Heaviside step function),今天的神经网络大多使用Relu激活函数。在卷积神经网络的最后一层,损失设置为多分类的对数损失函数categorical_crossentropy,这是对勒让德最小二乘法的一大改良,使用逻辑回归来解决多类别问题。另外优化算法Adam则起源于德比的梯度下降思想。此外, Tikhonov的正则化思想被广泛地应用于Dropout层和L1 / L2层的正则化函数。
未来优秀的人工智能学家必然是能够在人脑科学和数字科学这两个学界往来的学者。有科学家认为,深度学习网络最适合解决在输入的信号中消除噪音的问题,解决模拟自然视觉,语音识别等问题,这些也正是我们的大脑擅长应付的。
同时,人类的神经网络和人造数字神经网络都会遇到结论不确定的情况,从而使微小的差异无法消除。例如,对一个变量的变化非常敏感的逻辑问题并不适合深度学习来解决,比如离散问题和加密问题等。据一个例子,我觉得深度学习不会更像很多电影或者小说里说的那样成为超级人工智能黑客。破解密码和寻找系统漏洞并不是深度学习擅长做的事情(也不是人类擅长做的事情)。
